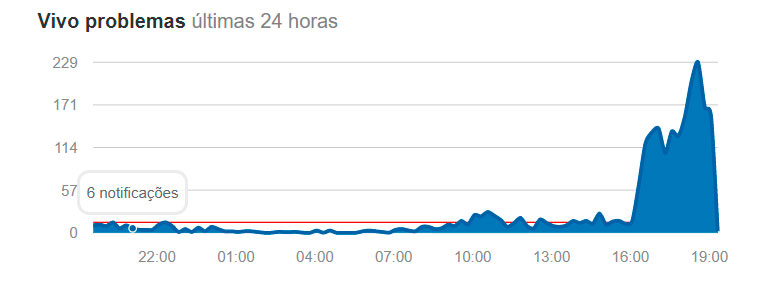
Instabilidade Vivo
:strip_icc()/i.s3.glbimg.com/v1/AUTH_63b422c2caee4269b8b34177e8876b93/internal_photos/bs/2022/A/x/BXOIm1QEGHc9BZ527iKA/234003548.jpg)
Este guia prático explica como identificar, diagnosticar e corrigir a instabilidade em tempo real de sistemas e dispositivos, ajudando você a manter operações estáveis e previsíveis. Ao aplicar as etapas descritas, você reduz travamentos, evita quedas inesperadas e ganha confiança no comportamento sob carga variável.
O que é instabilidade vivo e por que importa
A expressão instabilidade vivo refere-se a oscilações, travamentos ou comportamento imprevisível que surgem enquanto um sistema, aplicativo ou equipamento está em funcionamento ativo. Diferente de falhas estáticas, problemas de instabilidade ao vivo aparecem sob carga, tráfego intenso, uso prolongado ou condições de contorno, tornando-os mais difíceis de reproduzir em laboratório. Esses sintomas podem incluir latência alta, quedas de desempenho, reinicializações não planejadas, uso excessivo de memória ou CPU, e respostas inconsistentes entre requisições. Para arquitetos de software, engenheiros de infraestrutura e técnicos de campo, reconhecer a instabilidade em ambiente real é essencial para garantir disponibilidade, qualidade de serviço e experiência do usuário.
Como identificar os primeiros sintomas de instabilidade em andamento
A detecção precoce é a base para uma correção eficaz. Observe sinais leves que podem evoluir para falhas críticas se ignorados.
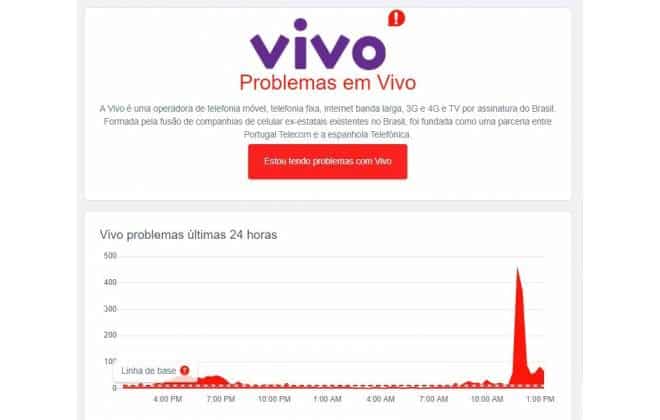
- Variações bruscas de latência ou tempo de resposta em cenários que antes eram consistentes.
- Uso anormal de recursos, como CPU picos, memória crescendo sem liberação ou disco sobrecarregado.
- Logs cheios de warnings, retries, timeouts ou mensagens de erro intermitentes.
- Comportamentos diferentes entre horários de baixa e de pico.
- Inconsistência em testes automatizados que, às vezes, passam e às vezes falham sem alteração aparente de código.
Quais são as causas mais comuns de instabilidade ao vivo
Antes de corrigir, convém mapear possíveis origens. Revisar cada categoria ajuda a reduzir o espaço de hipóteses.
Recursos limitados e contenção
Memória insuficiente, filehandles exaustos, conexões de banco de dados saturadas ou filas de mensagens sobrecarregadas podem criar gargalos que se manifestam como instabilidade em períodos de maior demanda.
Configuração inconsistente entre ambientes
Diferenças sutis entre estágios de desenvolvimento, homologação e produção, como timeouts, retries, pool sizes ou variáveis de ambiente, geram comportamentos imprevisíveis quando o tráfego real chega.
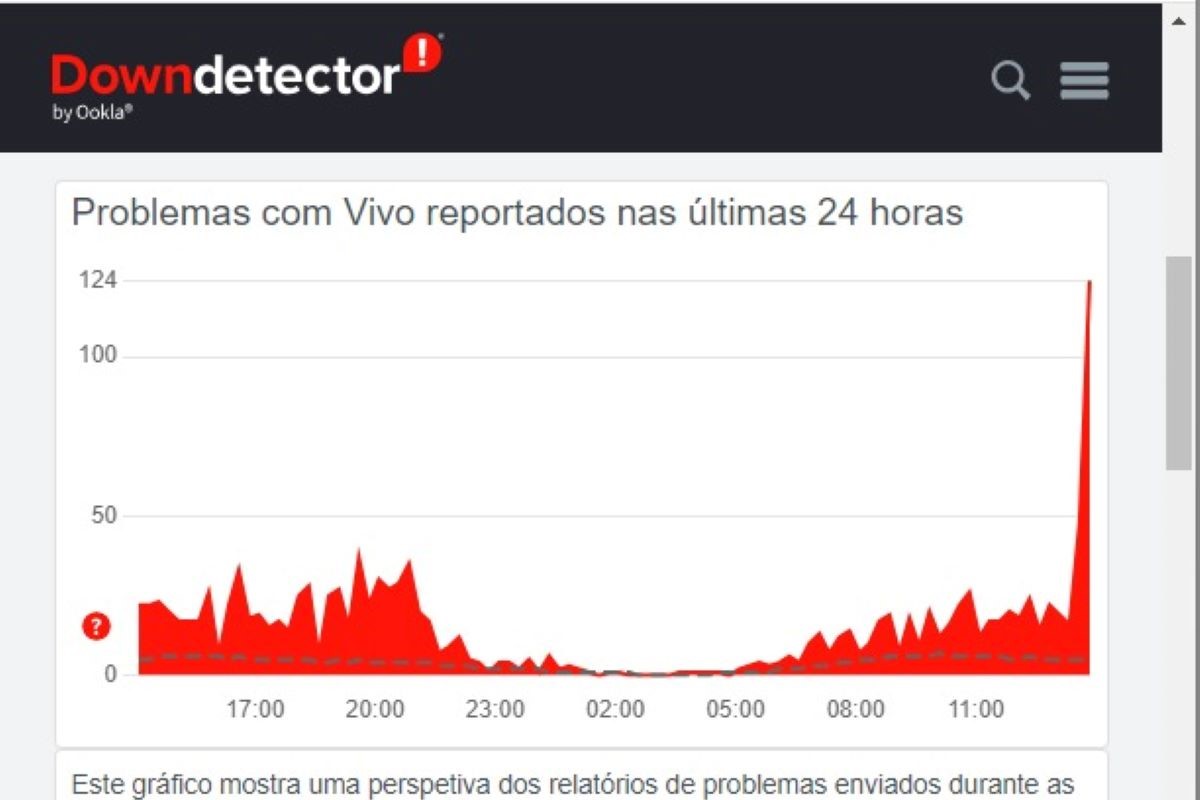
Vazamentos de recursos e gerenciamento inadequado
Objetos não liberados, conexões não retornadas ao pool, cache descontrolado ou acumulação de logs podem degradar o desempenho ao longo do tempo, levando a instabilidade relativa em sessões longas.
Externos e integrações frágeis
APIs de terceiros lentas, indisponíveis ou com rate limit, serviços de fila sobrecarregados ou dependências mal projetadas impactam diretamente a estabilidade do fluxo principal.
Como montar um ambiente favorável à investigação de instabilidade
Coletar dados confiáveis exige reproduzir o cenário o mais próximo possível do real, com observabilidade adequada.

- Habilite logs detalhados em nível de rastreamento, mas com controle de volume para evitar sobrecarga adicional.
- Ative métricas de sistema e de aplicação, como uso de CPU, memória, latency de resposta, taxas de erro e throughput.
- Incorpore tracing de transações para seguir uma requisição entre múltiplos serviços e identificar gargalos.
- Use ferramentas de profiling sob carga controlada para identificar vazamentos e pontos lentos.
- Consolide as configurações de forma que ambientes de teste reflitam fielmente as características de produção.
Quais passos seguir para diagnosticar instabilidade em andamento
- Reproduza o cenário com carga controlada, simulando padrões reais de acesso e picos de uso.
- Colete métricas de infraestrutura, incluindo CPU, memória, disco, rede, descritores de arquivo e threads.
- Examine logs e traces em busca de erros repetitivos, aumento gradual de uso ou padrões sazonais.
- Analise configurações de timeout, retry, circuit breaker e limites de pool em comparação com boas práticas e recomendações de fornecedores.
- Verifique integrações externas, latências de rede, SLA de provedores e possíveis pontos únicos de falha.
- Inspecione código em áreas de processamento assíncrono, concorrência, bloqueios e acesso a recursos compartilhados.
- Documente hipóteses, testes realizados e resultados para criar um backlog de ações corretivas.
Como corrigir e prevenir instabilidade em sistemas em produção
Após diagnosticado, aplique ajustes com validação contínua. Pequenas mudanças podem transformar drasticamente a resiliência.
- Ajuste limites de pool, timeouts e retry com base em dados observados, nunca apenas por suposição.
- Implemente backpressure, rate limiting e circuit breakers para isolar falhas e evitar efeitos em cascata.
- Otimize uso de memória, corrigindo vazamentos, ajustando caches e evitando retenção desnecessária de objetos.
- Estabeleça baselines de performance e monitore continuamente para detectar desvios precocemente.
- Automatize testes de carga e estouro de recursos para validar a capacidade de resposta em cenários extremos.
- Consolide configurações entre ambientes e mantenha documentação clara de parâmetros críticos.
- Planeje capacidade com crescimento de tráfego e estabeleça planos de contingência para picos sazonais ou eventos inesperados.
Quais ferramentas e requisitos você precisa para esse trabalho
- Plataforma de monitoramento e alertas em tempo real, como painéis com métricas de infraestrutura e aplicação.
- Coleta centralizada de logs com indexação e busca eficiente, facilitando a correlação de eventos.
- Ferramentas de tracing distribuído para mapear fluxos entre serviços e identificar latências críticas.
- Sistemas de gerenciamento de configuração e feature flags para promover lançamentos controlados e testes A/B.
- Frameworks de profiling e análise de performance compatíveis com a pilha tecnológica em uso.
- Acesso a méticas de SLA de provedores externos e dashboards de saúde de integrações.
- Ambientes de staging e carga que reproduzem fielmente o comportamento de produção para validação de mudanças.
Quais são os erros mais frequentes ao lidar com instabilidade
- Ignorar sinais iniciais porque o sistema "ainda funciona" em cenários leves.
- Testar apenas em ambientes leves, sem simular carga real e padrões de acesso variados.
- Focar apenas em logs de erro sem analisar métricas de performance e uso de recursos ao longo do tempo.
- Adicionar logs ou aumento de verbosidade em produção sem controle, gerando sobrecarga e dificultando a análise.
- Corrigir um sintoma pontual sem abordar a causa raiz, levando a recorrência em outros componentes.
- Alterar múltiplos parâmetros simultaneamente, tornando impossível identificar qual teve efeito positivo ou negativo.
- Subestimar a importância de configurações de timeout e retry, especialmente em chamadas a serviços externos.
Como transformar diagnósticos em melhorias duradouras
Use os insights da instabilidade para evoluir a arquitetura e as práticas de operação. Documente lições aprendidas, atualize runbooks e compartilhe conhecimento entre times. Estabeleça gatilhos de alerta antecipados, crie canais de comunicação rápidos para incidentes e incorpore testes de resiliência no ciclo de desenvolvimento. Com esse ciclo de feedback, o sistema torna-se mais robusto, previsível e capaz de enfrentar picos de carga sem comprometer a experiência do usuário.
Perguntas frequentes
Perguntas frequentes: instabilidade vivo pode indicar problema de hardware?
Sim, principalmente quando a instabilidade é acompanhada de erros de disco, temperatura anormal ou picos de energia. Nesses casos, revise logs de hardware e monitore sensores para descartar falhas físicas.
Perguntas frequentes: como diferenciar instabilidade de um aumento legítimo de carga?
Um aumento legítimo de carga mantém métricas dentro de padrões esperados, enquanto instabilidade revela comportamentos inconsistentes, como latência crescente, timeouts ou uso anormal de recursos mesmo com carga previsível.
Perguntas frequentes: devCorrigir instabilidade em ambientes distribuídos é mais complexo?
Sim, exige rastreamento transacional, correlação de logs entre serviços e atenção a problemas de rede, sincronia de relógios e configuração de tolerância a falnas em cada ponto da arquitetura.
Perguntas frequentes: quando devCorrigir instabilidade vivo em produção?
Se a instabilidade afeta disponibilidade ou qualidade do serviço, aplique correções com rollback planejado, monitore impacto em tempo real e use feature flags para controlegradual de mudanças.